Lakehouse vs Data Warehouse: What's the Difference and When to Use Each
I made a mistake in my second month as a data engineer.
Our startup was growing fast, three data sources had become twelve almost overnight. Product events from Mixpanel, orders from Shopify, support tickets from Zendesk, raw logs from our backend. I needed everything in one place, queryable, fast.
So I did what made sense at the time: I dumped everything into our Snowflake warehouse. Raw JSON blobs, unnested arrays, half-cleaned API responses — all of it, straight in.
Three weeks later, our BI team couldn't trust a single number. Our schema was a mess. Re-ingesting data cost us real money. And every new data source I added made things worse, not better.
That mess is what taught me the real difference between a Lakehouse and a Data Warehouse and more importantly, why you almost always need both.
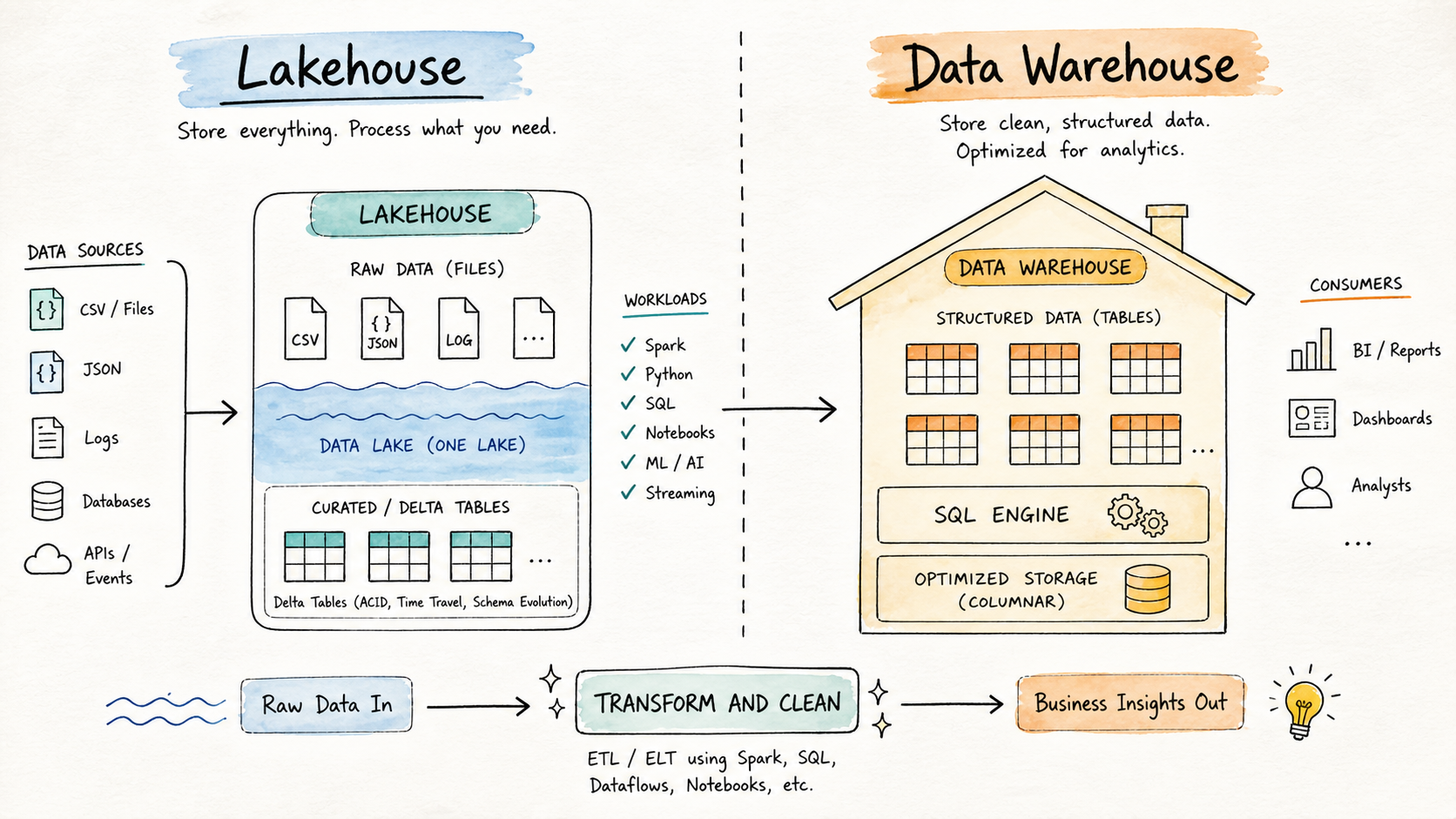
What Is a Data Warehouse?
After my Snowflake disaster, a senior engineer on the team pulled me aside and said something I didn't fully appreciate at the time:
"A warehouse is not a dumping ground. It's a showroom."
He was right. The Data Warehouse has been the backbone of business intelligence for decades precisely because it enforces discipline. Data must be cleaned and structured before it enters. No exceptions.
This is called schema-on-write, the shape of your data is defined upfront, and anything that doesn't fit gets rejected. That strictness feels like a constraint until you're the analyst trying to build a board-level revenue report and you actually need to trust the numbers.
Key characteristics:
-
- Designed for structured, cleaned, analytics-ready data
-
- Strict schema enforcement (schema-on-write)
-
- Highly optimized for SQL-based analytical queries
-
- Strong governance, security, and access controls
-
- Primary consumers are SQL analysts, BI teams, and business stakeholders
Platforms like Snowflake, Google BigQuery, Amazon Redshift, and Azure Synapse are well-known implementations. They excel when your data is already clean and your consumers need fast, reliable SQL access.
My mistake wasn't using Snowflake. It was using it for the wrong stage of the pipeline.
What Is a Lakehouse?
After the Snowflake incident, I started reading about data lakes. The pitch was appealing: store everything cheaply in raw form, figure out structure later.
So I tried that next. We set up an Azure Data Lake, dumped our raw files in - CSVs, JSONs, Parquet, logs and called it a win.
Except six months later, nobody could find anything. Data existed, but nobody trusted it. There was no validation, no versioning, no way to know if what you were querying was the right version of a file. We had built what the industry lovingly calls a data swamp.
The Lakehouse pattern emerged to solve exactly this problem. It takes the cost efficiency and flexibility of object storage, and adds a proper table layer on top using open formats like Delta Lake, Apache Iceberg, or Apache Hudi. You get ACID transactions, schema enforcement, time travel, and SQL access without abandoning the flexibility of raw storage.
Key characteristics:
-
- Stores raw, semi-structured, and structured data in a single system
-
- Uses open table formats (Delta Lake, Iceberg, Hudi)
-
- Supports multiple processing engines like Spark, Python, and SQL
-
- Schema can evolve over time as data needs change
-
- Supports both engineering pipelines and ML workflows from the same storage layer
Platforms like Databricks and modern cloud-native setups implement this pattern well. It's particularly powerful when your team spans both data engineering and data science — both can work from the same storage layer without stepping on each other.
Key Differences at a Glance
| Aspect | Lakehouse | Data Warehouse |
|---|---|---|
| Data Type | Raw, semi-structured, and structured | Structured only |
| Schema Approach | Schema-on-read or evolving | Schema-on-write, strict |
| Flexibility | High | Moderate |
| Processing Engines | Spark, Python, SQL | Primarily SQL |
| Primary Users | Data Engineers, Data Scientists | Analysts, BI teams |
| Primary Use Cases | Ingestion, transformation, ML | Reporting, dashboards, ad-hoc analytics |
| Governance Maturity | Developing | Mature, well-established |
| Storage Cost | Lower (object storage) | Higher (optimized proprietary storage) |
When to Use a Lakehouse
Think of the Lakehouse as the engineering zone.
In our case, this is where raw Shopify orders land at 2am, where Mixpanel event logs pile up, where our ML team runs experiments on customer behavior data. It's messy in the best possible way flexible, cheap, and tolerant of the chaos that comes with early-stage data.
Use a Lakehouse when:
- You are ingesting raw or semi-structured data from APIs, event streams, IoT devices, or application logs
- You need to run transformation and cleaning pipelines before data is analytics-ready
- Your team works primarily in Spark or Python
- Your schema changes frequently as business or source systems evolve
- You are building ML features, training datasets, or experimental models
- You need cost-efficient storage for large volumes of data at various stages of processing
If I had started here instead of going straight to Snowflake, I would have saved myself three weeks of firefighting.
When to Use a Data Warehouse
Think of the Data Warehouse as the consumption zone.
Once our data was cleaned and validated in the Lakehouse, we loaded curated datasets into Snowflake and that is when it finally worked the way it was supposed to. Our BI team connected Power BI to it, the finance team ran their monthly reports, and the numbers matched.
Use a Data Warehouse when:
- Data has already been transformed and is ready for consumption
- Your consumers are SQL analysts or BI teams using tools like Tableau, Looker, or Power BI
- You need fast, predictable query performance on large structured datasets
- Governance, row-level security, and access controls are critical requirements
- You are supporting stable, recurring reports that business decisions depend on
The warehouse isn't where data is processed. It's where processed data is served.
How They Work Together
Here's what nobody tells you early enough: you almost always need both.
Lakehouse and Data Warehouse are not competing choices. They serve different stages of the same data lifecycle. Once we restructured our setup, the flow looked like this:
- Raw data lands in the Lakehouse : Shopify orders, Mixpanel events, Zendesk tickets, all of it
- Our data engineers transform and clean it using Spark and dbt
- Curated, structured datasets are loaded into Snowflake
- Power BI and Tableau connect to Snowflake for dashboards and business reporting
The Lakehouse handled the complexity of early-stage data. The Warehouse handled the reliability of what our stakeholders actually saw. Each did what it was best at.
The moment we stopped treating them as alternatives and started treating them as sequential layers, everything clicked.
Choosing Between Them
If you're still unsure, here's the simplest filter I've found: ask who is consuming this data, and in what state.
- If the consumer is a data engineer or data scientist working with raw or intermediate data → Lakehouse
- If the consumer is an analyst or business user needing clean, structured data for reporting → Data Warehouse
- If you have both types of consumers (and most teams do after a few months of growth) → use both, in sequence
The workload determines the architecture. Not preference, not trend, not what a vendor happens to be marketing this quarter.
Conclusion
I wasted a month learning this the hard way. You don't have to.
The Lakehouse gives you flexibility, scale, and support for diverse workloads across engineering and data science. The Data Warehouse gives you structure, query performance, and the governance that business reporting demands.
They're not rivals. They're teammates. And the best data platforms I've seen since don't choose between them — they use each exactly where it belongs, and build the pipeline that connects them.
If you're in the early stages of designing your data platform and figuring out where each piece fits, I'd love to compare notes.

Improve this Blog Post
All our blog posts are open source. Found a typo, want to add more detail, or have a better explanation? Anyone can contribute and make this post better for everyone.