Why We Rolled Back Our Kafka Pipeline to Batch After 6 Months
Everyone in data engineering is obsessed with real time.
Kafka. Flink. Event-driven architectures. Millisecond latency. Live dashboards. It's the direction every conference talk points, every job description asks for, every architecture diagram proudly features.
And I bought into it completely.
About a year into my data engineering career, our product team came to us with a request: customers wanted to see their order status update in real time. Our existing batch pipeline ran at 2am every night, customers were calling support asking where their orders were.
Reasonable ask. So we rebuilt the pipeline as a streaming system.
Six months later, I had learned more about the real cost of streaming than any blog post or conference talk had ever prepared me for.
This is that story — and the honest breakdown I wish someone had given me before I started.
What We Had Before (And Why It Worked)
Our original order pipeline was batch. It ran every night at 2am via Azure Data Factory, pulled 24 hours of orders from our SQL database, ran a Spark transformation job, and wrote clean Delta tables to ADLS Gen2.
Every night at 2am:
↓
ADF Pipeline triggers
↓
Pull all orders from the last 24 hours
↓
Spark: clean → deduplicate → join product catalog
↓
Write to Silver layer (Delta table on ADLS Gen2)
↓
Aggregate into Gold layer
↓
Power BI refreshes — customers see updated status
It ran in 45 minutes. Our Spark cluster spun up, did its job, and shut down. We paid for 45 minutes of compute per day. The pipeline was simple, debuggable, and recoverable, if something broke, we fixed it and replayed from Bronze.
The only problem: customers saw data that was 6 to 30 hours old depending on when they ordered.
For most use cases, that's fine. For order status, it wasn't.
Hidden Cost #1 - Infrastructure That Never Sleeps
The first thing that surprised me about our streaming pipeline was the infrastructure bill.
Our batch Spark cluster ran 45 minutes a day. Our Kafka + Flink setup runs every minute of every day - 24 hours, 7 days a week, whether there are 10 events per second or 10,000.
Streaming infrastructure requires 24/7 uptime. You can't spin it down overnight to save money. You can't schedule it during off-peak hours. The pipeline is always on, always consuming resources, always incurring cost.
For our team, the monthly compute cost for the streaming pipeline was roughly 4x what the equivalent batch job cost and that was before accounting for the additional engineering time to maintain it.
The question to ask before going streaming: Is the business value of real-time data worth 4x the infrastructure cost? Sometimes the answer is yes. Often it isn't.
Hidden Cost #2 - Late-Arriving Data Will Break Your Logic
In a batch pipeline, late data is not a problem. If an event arrives 3 hours late, it's in the next batch. The pipeline processes it, life goes on.
In a streaming pipeline, late-arriving data is one of the hardest problems in distributed systems.
Events can arrive out of order due to network delays, retries, or clock skew between services. Your Flink job is processing event #1,000 when event #987 suddenly arrives 45 seconds late. What do you do?
The answer involves watermarking, telling your stream processor "wait X seconds after the event time before closing a window, to account for late arrivals." But choosing the right watermark is a balance:
- Too short: you miss late-arriving events, your aggregations are wrong
- Too long: you hold state in memory longer, increasing latency and memory pressure
We got this wrong twice before landing on a configuration that worked. Both times, our order counts were silently off by 1-3%, small enough to look like noise, large enough to cause problems in financial reconciliation.
Late data problem illustrated:
Event time: 10:00 10:01 10:02 10:03 10:04
Arrived at: 10:00 10:01 10:04 10:03 10:05
↑
event #3 arrived 2 minutes late
— already missed the 10:02 window
— your aggregate is wrong
In batch, this doesn't exist as a problem. In streaming, it's a constant engineering challenge.
Hidden Cost #3 - Exactly-Once Is Harder Than It Sounds
Handling failures in batch pipelines is usually predictable.
If a batch job fails, you typically resolve the issue and rerun the pipeline from the beginning. Since the processing happens on bounded data, recovery is relatively straightforward.
Streaming systems work very differently.
In platforms like Kafka and Flink, data is continuously flowing through the system. If a streaming job crashes midway through processing, recovery becomes much more complex than simply restarting the job.
For example, after recovery:
- Should previously processed events be replayed?
- Could some records get skipped unintentionally?
- Is there a possibility that certain events are processed more than once?
This challenge is commonly addressed through exactly-once processing guarantees, where the goal is to ensure that every event affects the system exactly one time even during failures and restarts.
Achieving reliable exactly-once behavior usually depends on several components working together correctly:
- Proper Kafka offset management
- Reliable Flink checkpointing and state recovery
- Idempotent writes to downstream systems
- Consistent state synchronization during failover scenarios
In practice, recovery bugs in streaming systems can have real operational impact. A single restart issue can lead to duplicate event processing, inconsistent downstream data, repeated customer notifications, or inaccurate analytics until the state is corrected.
Unlike batch systems, where failures often leave datasets untouched until rerun, streaming failures can leave systems in partially updated states that are significantly harder to debug and recover from.
Hidden Cost #4 - Testing Is a Different Discipline
Testing a batch pipeline is relatively straightforward. You have a dataset, you run the transformation, you check the output. Deterministic, reproducible, easy to validate.
Testing a streaming pipeline requires simulating event streams with realistic timing, ordering, and volume. You need to test:
- What happens when events arrive out of order?
- What happens when a consumer crashes and restarts?
- What happens when Kafka lag builds up during a traffic spike?
- What happens when an upstream service sends a malformed event?
We discovered most of our edge cases in production, not in testing. Not because we were careless, but because accurately simulating a live event stream in a test environment is genuinely difficult.
Our batch pipeline had a test suite that ran in 8 minutes. Our streaming pipeline's test suite took 40 minutes and still missed three production bugs in the first month.
Hidden Cost #5 - Your Team Needs Streaming-Specific Skills
This one is easy to underestimate.
Batch data engineering skills - Spark, SQL, dbt, ADF are well-understood, well-documented, and widely held. If someone on your team leaves, finding a replacement with those skills is manageable.
Streaming-specific skills Kafka internals, Flink state management, watermarking strategies, consumer group management, exactly-once configuration are genuinely harder to find and take longer to develop.
When we hit our first major Flink issue (a state backend misconfiguration causing memory pressure under load), our team spent three days debugging something that an experienced Flink engineer would have spotted in 20 minutes. We didn't have one. We learned on the job, which is fine but it was expensive learning.
Before committing to a streaming architecture, ask: does your team have the skills to maintain it? And if not, what's the cost of developing those skills or hiring them?
So When Is Streaming Actually Worth It?
None of this means streaming is wrong. It means streaming has a real cost that should be weighed against a real business need.
Streaming is worth it when the business problem genuinely cannot tolerate batch latency. Here's a clear test:
Reach for streaming when:
- Fraud needs to be detected before a transaction completes — batch latency means the fraud already happened
- A customer's app needs to reflect a change within seconds of it occurring
- A system needs to react to an event automatically — alerts, triggers, automated responses
- You're processing IoT sensor data where stale readings are dangerous, not just inconvenient
Stick with batch when:
- You're building monthly reports, financial summaries, or historical analyses
- Your stakeholders check dashboards in the morning, not the second
- Your transformations involve complex aggregations over large historical datasets
- Your team is small and operational simplicity matters more than latency
The tech industry is currently obsessed with "real-time," which has led many organizations to over-engineer their stacks implementing complex stream-processing frameworks where a simple batch job would have sufficed. A well-built batch pipeline is more reliable, cheaper, and easier to maintain than a poorly-justified streaming one.
The Architecture That Actually Works: Both
Here's what I'd tell myself before starting that project:
You probably need both, not either/or.
Our final architecture uses batch for everything that can tolerate it, and streaming only for the specific cases that genuinely can't:
Streaming layer (Kafka + Flink):
Order events → real-time status updates (Cassandra)
Fraud signals → real-time alerts (notification service)
Batch layer (Spark + ADF):
Nightly order aggregations → Silver → Gold (Power BI)
Monthly revenue reports (finance team)
ML training datasets (data science team)
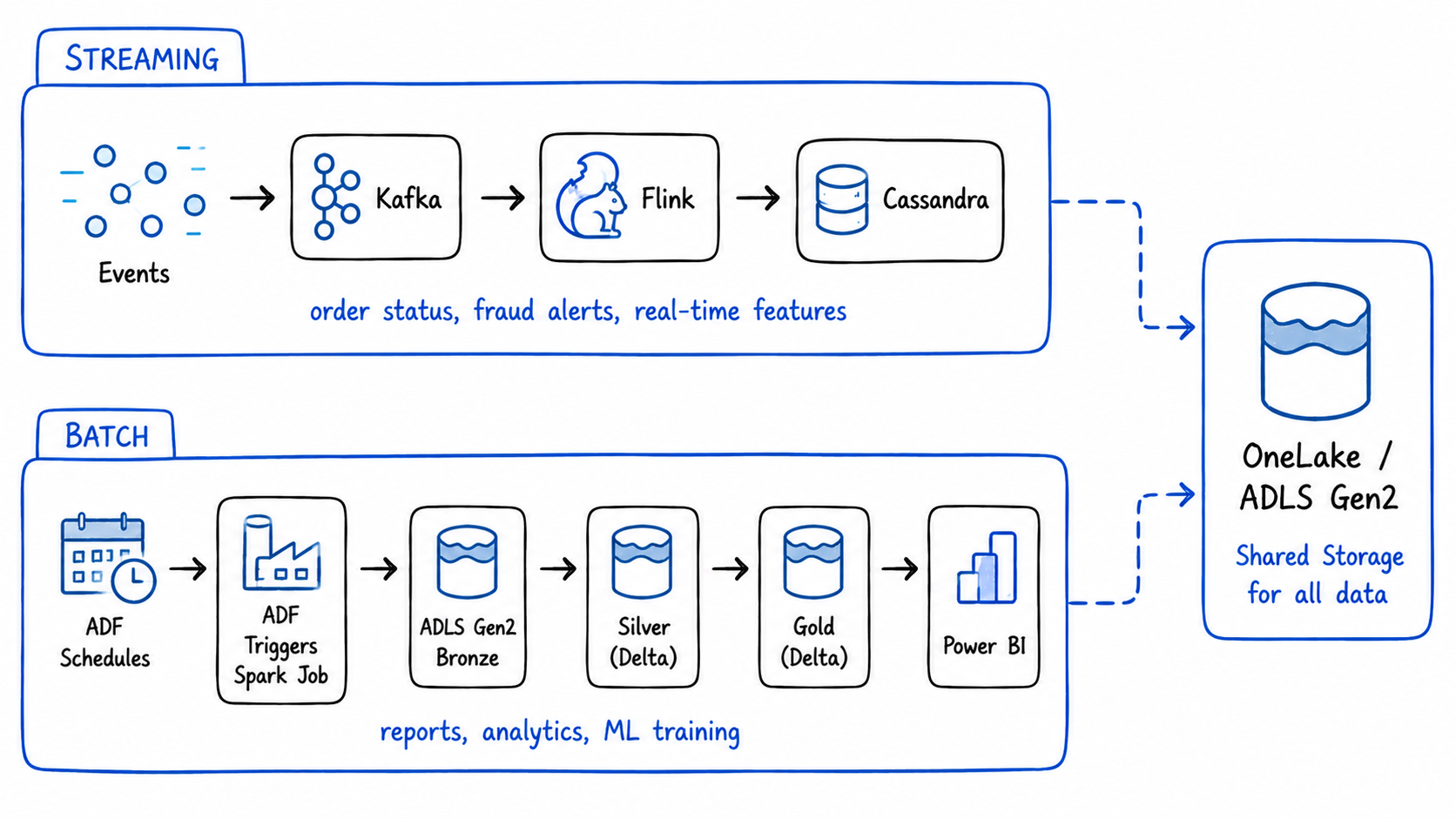
The streaming layer handles the 5% of use cases where seconds matter. The batch layer handles the 95% where they don't , more reliably, more cheaply, with less operational overhead.
Microsoft Fabric is built around exactly this pattern, Eventstreams for real-time ingestion, ADF Pipelines and Spark Notebooks for batch transformation, both writing to the same OneLake. You don't have to choose one architecture. You choose the right tool for each use case within the same platform.
The Honest Summary
| Batch | Streaming | |
|---|---|---|
| Infrastructure cost | Low - runs on schedule | High - always on |
| Latency | Minutes to hours | Milliseconds to seconds |
| Late data | Not a problem | Significant engineering challenge |
| Failure recovery | Fix and rerun | Complex - risk of duplicates or data loss |
| Testing | Straightforward | Requires stream simulation |
| Team skills needed | Spark, SQL, ADF | Kafka, Flink, state management |
| Best for | Analytics, reporting, ML | Fraud detection, live status, alerts |
| Operational complexity | Low | High |
Streaming pipelines are powerful. They enable product experiences that batch simply can't deliver.
But they come with real costs - infrastructure that never sleeps, late-data handling that never stops being tricky, failure recovery that's genuinely hard to get right, and a skills requirement that's easy to underestimate.
The next time someone on your team says "we should make this real time", ask the question first:
How long can the business actually wait for this data?
If the honest answer is "overnight is fine" — keep the batch job. It's not boring. It's the right call.
References & Further Reading
- Databricks - Batch vs Streaming
- Apache Flink - Watermarks and Late Data
- Apache Kafka Documentation
- Microsoft Fabric - Real-Time Intelligence
- RecodeHive - How Netflix Handles Millions of Events Every Minute
- RecodeHive - Medallion Architecture Explained
- RecodeHive - Microsoft Fabric: One Platform, One Lake
About the Author
I'm Aditya Singh Rathore, a Data Engineer passionate about building modern, scalable data platforms. I write about data engineering, Azure, and real-world pipeline design on RecodeHive, turning hard-won lessons into content anyone can learn from.
📩 Have you been burned by a streaming pipeline that didn't need to be? Drop it in the comments.

Improve this Blog Post
All our blog posts are open source. Found a typo, want to add more detail, or have a better explanation? Anyone can contribute and make this post better for everyone.